
Regularly collecting and analyzing data is an important component in the development of athletes, rehabilitative, and/or general populations. While there are specifics regarding how we use this data, please see a previous blog HERE, the purpose of this post is to explain how we decide what tests to run, and how often to re-test.
Before we think about the frequency, or when to complete the testing, the first thing to consider is simply, ‘Do we have the ability to complete this test?’. This comes down to equipment, space constraints, and economical factors.
If we have the actual ability to use a test, the next step would be to determine if the data can be counted on. This reliability is critical, as data with large amounts of ‘noise’ are difficult to understand. Does the person or group ‘improve’ due to in-accurate equipment? Did they get ‘worse’ because the testing protocol was too complex and an important step was forgotten? Due to the importance of reliability, any scientist should be sure that the measurement tools and collection procedures are well studied, in similar populations, and have detailed statistics (e.g., intraclass correlation coefficient, coefficient of variation, typical error) reported in the scientific literature.  In many cases, research lags behind new products. In this situation, the scientist and/or practitioner should run a ‘pilot study’ where the reliability of a device or method is tested by completing the test on several people, over several occasions. We have done this many times at Acumen to better ensure our tests have acceptable noise (See our scientific publication HERE).
In many cases, research lags behind new products. In this situation, the scientist and/or practitioner should run a ‘pilot study’ where the reliability of a device or method is tested by completing the test on several people, over several occasions. We have done this many times at Acumen to better ensure our tests have acceptable noise (See our scientific publication HERE).
After ensuring data reliability, it is also important to choose tests that are ‘valid’ or for the specific population (e.g., bull-rider, ACL reconstruction). Often these come down to simple logic, or the eye test. Does the test look similar to the activity that the person(s) is working towards? If the athlete needs to be a good jumper to succeed, then a testing battery without some sort of jump test is clearly incomplete. 
 Other times, the research guides our test selection and correlational studies help here. For example, our cross-sectional Rodeo study found that riders with greater hip adduction forces (goin strength) were often more successful riders than their peers. Therefore, it would be logical to train, test, and track groin strength in the Rodeo athletes that we work with. There is, however, a downside to using cross-sectional studies, and ‘correlation does not always equal causation’. Therefore, ideally, longitudinal studies exist (Examples 1, 2 here) demonstrating that improvements in a specific test are likely to predict better clinical or athletic outcomes for client(s).
Other times, the research guides our test selection and correlational studies help here. For example, our cross-sectional Rodeo study found that riders with greater hip adduction forces (goin strength) were often more successful riders than their peers. Therefore, it would be logical to train, test, and track groin strength in the Rodeo athletes that we work with. There is, however, a downside to using cross-sectional studies, and ‘correlation does not always equal causation’. Therefore, ideally, longitudinal studies exist (Examples 1, 2 here) demonstrating that improvements in a specific test are likely to predict better clinical or athletic outcomes for client(s). 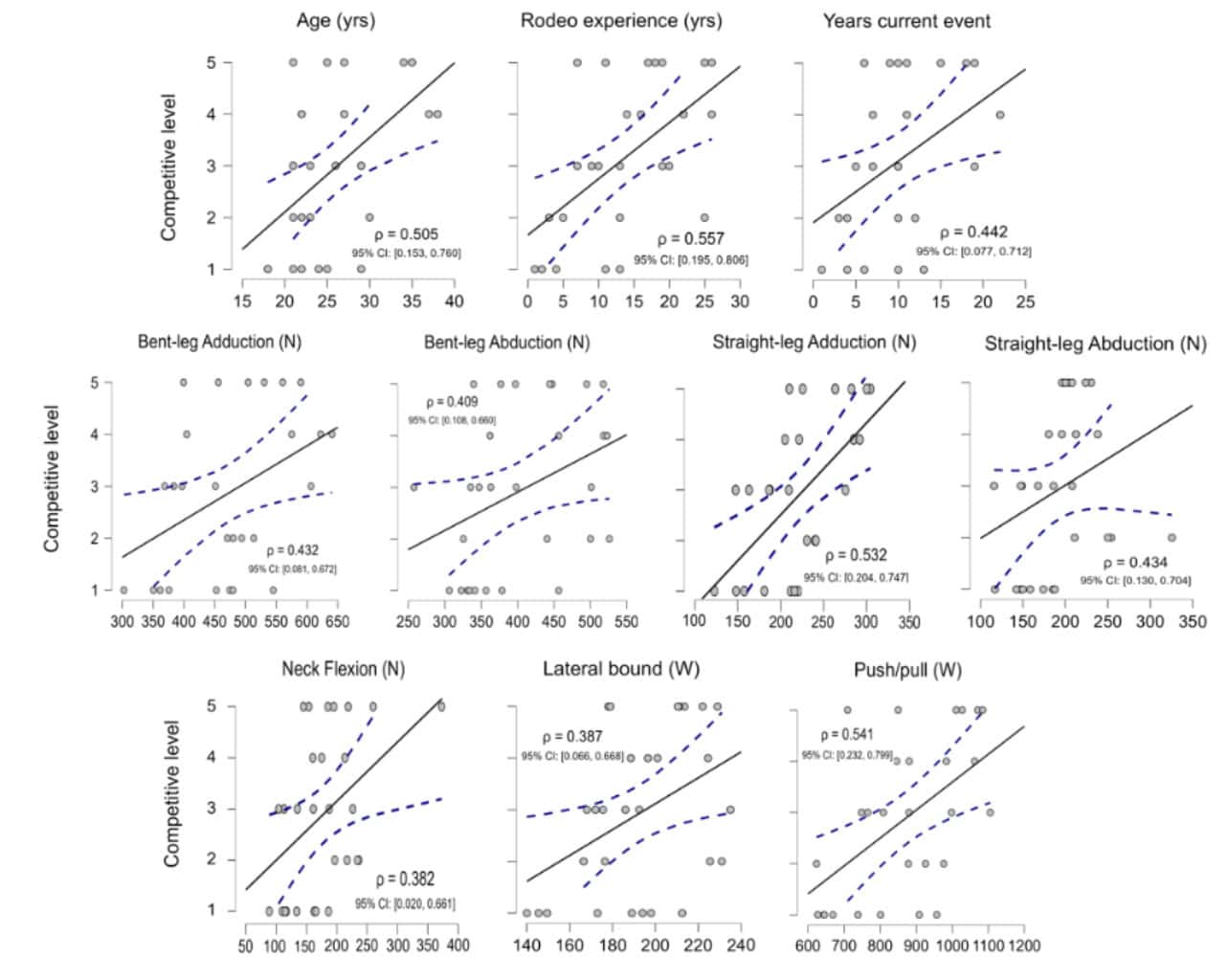 Of course, just because a test is reliable or valid, does not necessarily mean that an athlete or patient is capable of executing it. Jumping height may be a valid and reliable test, but a person fresh out of an ACL reconstruction is several weeks, or even months away from being able to safely and confidently perform a maximal jump test. Therefore, we can ‘bridge the gap’ and still collect useful and potentially motivating data by assessing ranges of motion, perceptual, and strength using safe and non-intimidating tests.
Of course, just because a test is reliable or valid, does not necessarily mean that an athlete or patient is capable of executing it. Jumping height may be a valid and reliable test, but a person fresh out of an ACL reconstruction is several weeks, or even months away from being able to safely and confidently perform a maximal jump test. Therefore, we can ‘bridge the gap’ and still collect useful and potentially motivating data by assessing ranges of motion, perceptual, and strength using safe and non-intimidating tests.
In short, when determining the tests we use when collecting data, it is always important to be aware of what questions you would like answered and how we can do so with the most certainty. This is why we have developed different testing protocols for the various athletes/teams, injury rehabilitation, and general population that we work with. Everyone has different needs and our data needs to consider that.




